Apache beam at Shine — part I


Publié le 10 février 2022
par Pascal Delange
6 min. de lecture
Publié par Pascal Delange
Mis à jour le 4 juillet 2023
6 min
Since 2017, our data team has grown with the company, and is responsible for developing mission-critical parts of our back-end tooling covering a wide range of topics, from ETL pipelining to fraud monitoring to document analysis for our operations teams.
In this series of blog posts, we want to discuss some of the tools we are using, to share what we have learned but also to collect feedback from fellow users. In this post, we will cover one of the tools we use most heavily, that we consider a great addition to every data engineer’s toolbox: Apache beam (also known as Cloud Dataflow on Google Cloud, where our servers are hosted and where it originated).


So, what is Apache beam for?
Shine’s back-end is built as a loosely-coupled micro-services architecture (written in node.js, typescript and python), and this design has served us well since we launched four years ago. However, many tasks handled by the data team are embarrassingly parallel, and we like to be able to run similar jobs in a batch or streaming mode with minimal effort. Typically, we do this to retry failed events or to use streaming and batch data sources with the same side effects. We also tend to tend to handle large volumes of data, work in python most of the time, and like to run all our infrastructure on a unified Google Cloud project.
Apache beam ticks all these boxes and was thus a great fit. To cite the official documentation,
Apache Beam is an open source, unified model for defining both batch (corresponding to bounded data sources) and streaming (for unbounded data) data-parallel processing pipelines, […] particularly useful for embarrassingly parallel data processing tasks
It was initially developed by Google, which open-sourced and handed the project over to the Apache foundation in 2016. It comes with three different SDKs (Java, Python and Go, in decreasing order of age and completeness) and several compatible data processing back-ends, the Dataflow Runner being one of them. But enough paraphrasing the documentation and Wikipedia, let us dig into why and how we use it at Shine.
Below are some more specific examples of how we use Apache beam jobs:
ETL (“extract-transform-load”) scripts. For instance, we listen to a list of Pub/Sub events for all database insertions or updates and stream the formatted — and if necessary enriched — payloads into Spanner (which serves as our main operational database) and BigQuery (BQ, our data warehouse) tables to keep an audit trace of all actions taken with our APIs. Similarly, we stream the events into an Elasticsearch cluster for better full-text search of some entities. Failed events are streamed into BigQuery anyway to be retried later in a batch job.


Pub/Sub to Beam to Elasticsearch
Another job comes in two flavors: a streaming job listens to requests for one-off accounting exports, generates a temporary json file with all the necessary data, saves the file to Cloud Storage (GCS), and forwards a link to the file to a Cloud Function that handles the actual end user file and email sending. A very similar batch job is run every few hours to retry the generation of any missing accounting exports, and a last batch job runs every day to generate recurring exports.


Our more complicated database migrations are run using beam scripts. This allows for scalability (the jobs will scale to as many workers as needed to complete work in reasonable time), standardization (all migrations start from the same template), and access and rights management (the jobs are run using a dedicated service account by the Dataflow workers). Only the simplest migrations (namely, those that target few rows or do not involve joins) are run using a Data Manipulation Language (DML) command.
So, what does an actual beam job look like?
Writing an Apache beam job amounts to defining a directed acyclic graph (or DAG), made of nodes (known as “transforms”) acting on data “collections” (the edges of the graph). The top layer of transforms corresponds to data sources, and every transform can apply arbitrary code to the input elements (including side effects) and send data to zero or more downstream collections. Data from one or more collections can be grouped by key, using one of several flavors of time windows in the case of a streaming job.
The execution graph of our job that streams events to Elasticsearch looks as follows (the full DAG is on the left-hand side, with the here simplified detail of the “Read pubsub input” transform on the right-hand side):

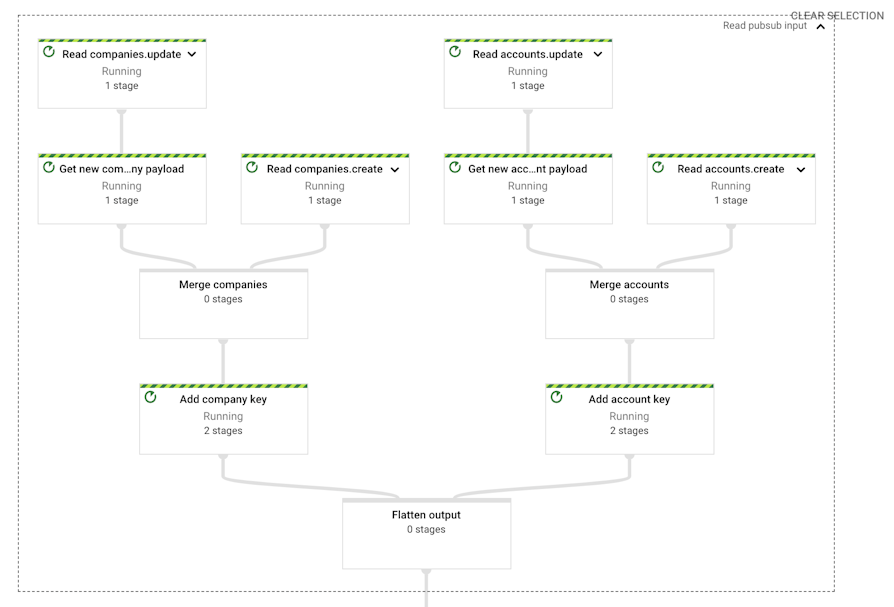
Example execution DAG for a Pub/Sub to Elasticsearch pipeline
A simplified version of the corresponding code might look like this (we have been early adopters of the python SDK since it allowed streaming pipelines in private beta version in 2017):
https://gist.github.com/pascaldelange/ea1a0907559a2d4bd5706d1d51f2c91b#file-etl-py
Most of the actual business logic happens in the second transform (“Write to elasticsearch”) and we can easily change the source to read from BQ, for instance.
As similar as streaming and batch execution might be, in terms of monitoring and error handling, the two modes pose rather different challenges. We will discuss the problem of monitoring our pipelines in a later blog post.
Orchestration of batch jobs
While streaming jobs are designed to be running 100% of the time, most of our batch jobs are designed to be executed periodically, with a frequency ranging from hourly to daily.
Initially, we had an Google App Engine (GAE) flex instance running cron jobs, with every cron job corresponding to one of our batch jobs. This served us well for a time, but had some important flaws:
The most important one is that we could not force jobs to run sequentially, other than by keeping a large enough time difference between the two schedules and hoping that the execution would not overlap.
Because the cron endpoints would return a 200 status as soon as the job was started, monitoring of jobs that failed during the execution was complicated.
There is only one shared cron.yaml file for the whole GAE project, which was becoming inconvenient.
Deployments of GAE flex are rather slow.
To improve on this, and because we needed to set this tool up for other projects anyway, we decided in 2020 to migrate all our periodic batch job handling to an Apache Airflow cluster (run on Cloud Composer). In our new architecture, a first repository contains the code for all our beam DAG templates, that are uploaded to GCS every time we merge a pull request (by passing the template_location option to the pipeline_options in the Gist above), while another repository contains the list of Airflow DAGs. We profited from this migration to also start using beam templates rather than having the job definition and scheduling logic in the same place (as we used to do on GAE) and launch those templates on Airflow (the preferred way of launching beam jobs) as below:
https://gist.github.com/pascaldelange/4d0859106b7e943872a78bfeff575a2a#file-airflow_dag-py
In particular, we gain a callback that will post a message on a slack channel if the job fails to complete.
Up next
In the following posts, we will discuss some of the difficulties we encountered while using Apache beam / Dataflow, and how we managed to circumvent or deal with some of them. Expect to read about error handling and retries, CI/CD and testing, private libraries, and other things!
In the meantime, if you are also using beam, we would love to hear about your use cases and to discuss your experience running it in production!










